


xml解析概述
当将数据存储在XML后,我们就希望通过程序获得XML的内容。如果我们使用Java基础所学习的IO知识是可以完成的,不过你需要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。人们为不同问题提供不同的解析方式,并提交对应的解析器,方便开发人员操作XML。
常见的解析方式和解析器
开发中比较常见的解析方式有三种,如下:
1、DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象。
-
优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
-
缺点:XML文档过大,可能出现内存溢出显现。
2、SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都将触发对应的事件。(了解)
-
优点:处理速度快,可以处理大文件。
-
缺点:只能读,逐行后将释放资源。
3、PULL:Android内置的XML解析方式,类似SAX。(了解)
- 解析器:就是根据不同的解析方式提供的具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包。

常见的解析开发包:
-
JAXP:sun公司提供支持DOM和SAX开发包。
-
JDom:dom4j兄弟。
-
jsoup:一种处理HTML特定解析开发包。
-
dom4j:比较常用的解析开发包,hibernate底层采用。
SAX解析XML
概述
SAX是Simple APl for XML的缩写,SAX是读取和操作XML数据更快速、更轻量的方法。SAX允许你在读取文档时处理它,从而不必等待整个文档被存储之后才采取操作。它不涉及DOM所必需的开销和概念跳跃。SAX API是一个基于事件的API,适用于处理数据流,即随着数据的流动而依次处理数据。SAX API在其解析你的文档时发生一定事件的时候会通知你。在你对其响应时,你不作保存的数据将会被抛弃。
SAX API中主要有四种处理事件的接口,它们分别是ContentHandler,DTDHandler,EntityResolver和ErrorHandler。实际上只要继承DefaultHandler类就可以,DefaultHandler实现了这四个事件处理器接口,然后提供了每个抽象方法的默认实现。
SAX解析采用的是事件驱动,通过事件回调的方式调用DefaultHandler中的事件处理方法。
SAX解析是高效省内存,事件驱动,但不灵活,只能顺序读取与解析,通常在移动开发中使用较多,WEB开发中使用少。
使用
person.xml
<?xml version="1.0" encoding="UTF-8" ?>
<people>
<person personId="E01">
<name>Tom</name>
<age>18</age>
</person>
<person personId="E02">
<name>Mary</name>
<age>20</age>
</person>
</people>
person.java
public class Person {
private String personId;
private String name;
private int age;
//省略构造方法、getter()、setter()、toString()
}
PersonHandler.java
package com.coydone;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import java.util.ArrayList;
import java.util.List;
public class PersonHandler extends DefaultHandler {
private List<Person> list = null;
private Person person; //当前正在解析的person
private String tag; //用于记录当前正在解析的标签名
public List<Person> getList() {
return list;
}
//开始解析文档时调用
@Override
public void startDocument() throws SAXException {
super.startDocument();
list = new ArrayList<>();
System.out.println("开始解析xml");
}
//在xml文档解析结束时调用
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("解析xml结束");
}
/**
* 解析开始元素是调用
* @param uri 命名空间
* @param localName 不带前缀的标签名
* @param qName 带前缀的标签名
* @param attributes 当前标签的属性集合
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if ("person".equals(qName)) {
person = new Person();
String personId = attributes.getValue("personId");
person.setPersonId(personId);
}
tag = qName;
}
//解析结束元素时调用
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if ("person".equals(qName)) {
list.add(person);
}
tag = null;
}
//解析文本内容时调用
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
if (tag != null) {
if ("name".equals(tag)) {
person.setName(new String(ch,start,length));
} else if ("age".equals(tag)) {
person.setAge(Integer.parseInt(new String(ch,start,length)));
}
}
}
}
Test.java
package com.coydone;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.InputStream;
import java.util.List;
public class Test {
public static void main(String[] args) throws Exception {
//创建SAX解析器工厂对象
SAXParserFactory spf = SAXParserFactory.newInstance();
//使用解析器工厂创建解析器实例
SAXParser saxParser = spf.newSAXParser();
//创建SAX解析器要使用的事件侦听器对象
PersonHandler handler = new PersonHandler();
//开始解析文件
InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream("person.xml");
saxParser.parse(is, handler);
List<Person> people = handler.getList();
people.forEach(System.out::println);
}
}
DOM4J解析XML
需要的jar包:DOM4J:dom4j-1.6.1.jar、xpath:jaxen-1.1.6.jar。
DOM解析原理和结构模型
XML DOM 将整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作。

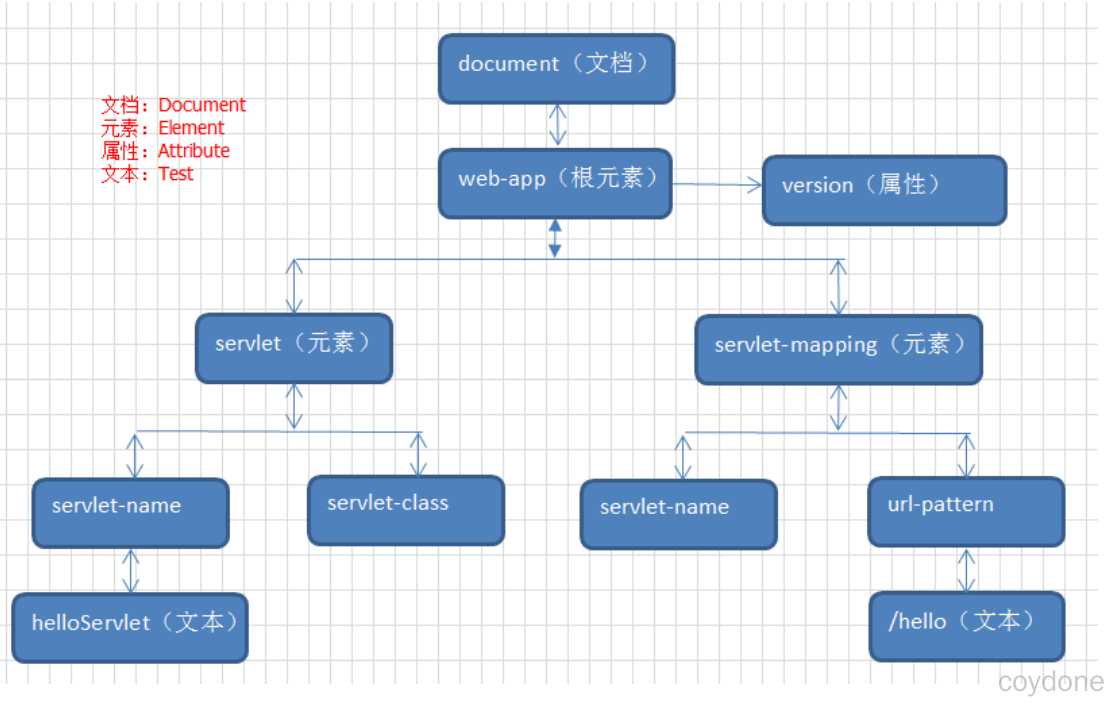
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本等,在DOM中都是节点。
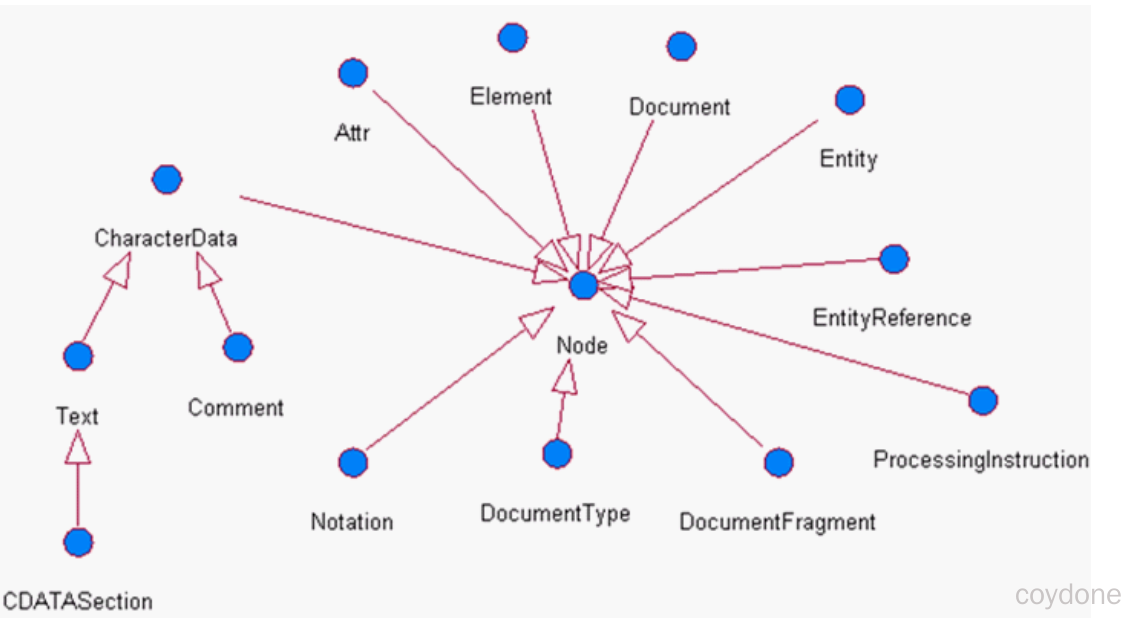
API使用
DOM4J是一个Java的XML API,具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,如今可以看到越来越多的Java软件都在使用DOM4J来读写XML。
如果想要使用DOM4J,需要引入支持xpath的jar包 dom4j-1.6.1.jar
DOM4J必须使用核心类SaxReader加载xml文档获得Document,通过Document对象获得文档的根元素,然后就可以操作了。
常用API如下:
1、SaxReader对象:read(…),加载执行xml文档。
2、Document对象:getRootElement(),获得根元素。
4、Element对象
-
elements(…):获得指定名称的所有子元素。可以不指定名称 element(…) 获得指定名称第一个子元素。可以不指定名称 getName() 获得当前元素的元素名。
-
attributeValue(…):获得指定属性名的属性值。
-
elementText(…):获得指定名称子元素的文本值。
-
getText():获得当前元素的文本内容。
API案例实现
编写xml文件 beans.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="001" className="com.coydone.demo.User">
<property name="user" value="jacl">郭德纲</property>
<property name="user" value="rose">柳岩</property>
</bean>
<bean id="002" className="com.coydone.demo.Admin">
<property name="user" value="admin">小岳岳</property>
<property name="user" value="write">佟丽娅</property>
</bean>
</beans>
编写解析xml代码
package xml;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
/*
* 使用dom4j的第3方的jar包来对xml进行解析
* 使用的是DOM的操作
* */
public class Dom4jDemo {
public static void main(String[] args) throws Exception {
/*创建SaxReader对象:核心对象*/
SAXReader sax = new SAXReader();
/*dom4j方式来读:先把xml文档放在内存里,把结构先整理好,再读*/
/*返回document对象*/
Document document = sax.read("xml/xml/beans.xml");
/*获取根节点*/
Element rootElement = document.getRootElement();
/*获取所有的子节点*/
List<Element> elements = rootElement.elements();
for (int i = 0; i < elements.size(); i++) {
/*获取bean元素名*/
System.out.println(elements.get(i).getName());
String id = elements.get(i).attributeValue("id");
/*attributeValue:获取元素的属性名和值*/
String className = elements.get(i).attributeValue("className");
System.out.println(id+"==="+className);
/*获取property的节点*/
List<Element> propertyElements = elements.get(i).elements();
for (Element propertyElement : propertyElements) {
String name = propertyElement.getName();
System.out.println(name);
/*找到property的属性和值*/
String name1 = propertyElement.attributeValue("name");
String value = propertyElement.attributeValue("value");
/*获取文本内容*/
String text = propertyElement.getText();
System.out.println("\t"+name1+"==="+value+"==="+text);
}
}
}
}
XPath解析XML
XPath 是一门在 XML、html 文档中查找信息的语言。
XPath 是一个 W3C 标准,可通过W3CSchool文档查阅语法。
由于DOM4J在解析XML时只能一层一层解析,所以当XML文件层数过多时使用会很不方便,结合XPATH就可以直接获取到某个元素。
使用DOM4J支持XPath具体操作
默认的情况下,DOM4J不支持XPath,如果想要在DOM4J里面使用XPath,需要引入支持XPath的jar包 jaxen-1.1.6.jar。
在dom4j里面提供了两个方法,用来支持xpath。
List<Node> selectNodes("xpath表达式"),用来获取多个节点Node selectSingleNode("xpath表达式"),用来获取一个节点
XPath表达式常用查询形式
-
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB -
//BBB: 表示和这个名称相同,表示只要名称是BBB 都得到 -
/*:所有元素 -
BBB[1]:表示第一个BBB元素BBB[last()]:表示最后一个BBB元素 -
//BBB[@id]: 表示只要BBB元素上面有id属性 都得到 -
//BBB[@id='b1']表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是 b1
案例实现
编写xml文件 student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="coydone_0001">
<name id="coydone">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>女</sex>
</student>
<student number="coydone_0002">
<name>jack</name>
<age>18</age>
<sex>男</sex>
</student>
</students>
编写XPath代码解析xml文件
package xml;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.util.List;
/*
* XPath;快速查找节点
* */
public class XPathDemo {
public static void main(String[] args) throws Exception {
/*核心对象*/
SAXReader sax = new SAXReader();
/*读取对应的xml文件*/
Document document = sax.read("xml/xml/student.xml");
/*xpath表达式:xml文件查找内容的路径*/
/*selectNodes:查找多个节点*/
List<Element> list = document.selectNodes("//students//student//name");
for (Element element : list) {
System.out.println(element.getName());
}
/*selectSingleNode:查找单个节点*/
Element element = (Element) document.selectSingleNode("//students//student//name//xing");
System.out.println(element.getText());
List<Element> list1 = document.selectNodes("//sex");
for (Element element1 : list1) {
System.out.println(element1.getText());
}
Element element1 = (Element)document.selectSingleNode("//student[last()]");
System.out.println(element1.attributeValue("number"));
Element element2 = (Element) document.selectSingleNode("//name[@id='coydone']");
System.out.println("id:"+element2.attributeValue("id"));
}
}
xStream组件
使用Java提供的java.beans.XMLEncoder和java.beans.XMLDecoder类。这是JDK 1.4以后才出现的类,可以根据对象生成XML文档。
//步骤:
1、实例化XML编码器
XMLEncoder xmLEncoder = new XMLEncoder(
new BufferedOutputStream(new FileOutputStream(new File("a.xml")))
);
2、输出对象
3、关闭
//把对象转成XML文件写入
public void xmlEndoder() throws FileNotFoundException {
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("test.xm1" ));
XMLEncoder xmlEncoder = new XMLEncoder(bos);
Person p = new Person();
p.setPersonId("1212");
p.setAddress("北京");
p.setEmail("coydone@163.com");
p.setTel("13838389438");
p.setName("38");
xmlEncoder.writeobject(p);
xmlEncoder.close();
}
//从XML文件中读取对象
public void xmlDecoder() throws FileNotFoundException {
BufferedInputStream in = new BufferedInputStream(new FileInputStream("test.xm1" ));
XMLDecoder decoder = new XMLDecoder(in);
Person p = (Person) decoder.readObject();
System.out.println(p);
}
通过对象生成XML文件:xStream组件可以快速的在xml文件与对象之间转换,这对于使用xml作为信息传输格式来说,尤其方便。xstream包依赖xpp3包。
//使用第三方xstream组件实现XML的解析与生成
public void xstream () {
Person p = new Person();
p.setPersonId("1212");
p.setAddress("北京");
p.setEmail("vince@163.com") ;
p.setTel("13838389438");
p.setName("38");
//对象→xml
XStream xStream = new XStream(new Xpp3Driver());
xStream.alias("person",Person.class);//别名
//设置personId为属性值
xStream.useAttributeFor(Person.class,"personId");
String xml = xStream.toXML(p);
System.out.println (xml) ;
//解析XML
Person person = (Person) xStream.fromXML(xml);
}
总结
1、认识XML和HTML区别?
-
XML 标签可以自定义 ,语法严格,区分大小写,存储数据,读取数据。(数据传输)。
-
HTML标签预定义,作用:展示内容 语法不严格 ,不区分大小写
2、约束 : DTD schema 用来约束xml的格式书写。
3、命名空间 : 区别引入的DTD/schema 约束文件的元素和属性。
4、XML解析:我们一般结合2种一起使用。
-
Dom4j:根据dom节点,一层一层的去解析:节点→属性→文本。
-
XPath:根据dom节点去查找,速度快。


评论区